
Custom R Component - Appstam Consumer Sentiment Analysis
|

|
Introduction
With Twitter and Facebook on the rise companies increasingly mine social networks to learn about their customers. The extension Appstam Consumer Sentiment Analysis uses Naive Bayes Classification to classify text documents like customer feedback or tweets: A text document will be assigned to one of two categories, like 'positive' or 'negative'. It allows for brand sentiment analysis in languages that are not yet supported by the build in HANA text mining ( consumer sentiment analysis modules ), such as Swedish or Dutch, in real time.
How to upload the component in SAP Predictive Analytics
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
With Twitter and Facebook on the rise companies increasingly mine social networks to learn about their customers. The extension Appstam Consumer Sentiment Analysis uses Naive Bayes Classification to classify text documents like customer feedback or tweets: A text document will be assigned to one of two categories, like 'positive' or 'negative'. It allows for brand sentiment analysis in languages that are not yet supported by the build in HANA text mining ( consumer sentiment analysis modules ), such as Swedish or Dutch, in real time.
How to upload the component in SAP Predictive Analytics
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Extension Features
The extension consists of an estimation and prediction function (the primary and model scoring function). This allows to train and test the model on labeled data and then save and apply it to new unlabeled data. In addition, both parts provide a wordcloud as a custom chart. A wordcloud visually represents the text data based on word frequency.
The extension consists of an estimation and prediction function (the primary and model scoring function). This allows to train and test the model on labeled data and then save and apply it to new unlabeled data. In addition, both parts provide a wordcloud as a custom chart. A wordcloud visually represents the text data based on word frequency.
Usage
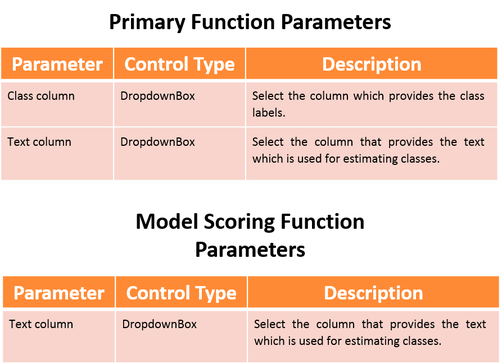
These parameters can be set by the user:
These parameters can be set by the user:
Extended Example
The following extended example shows how you could use the extension in a productive scenario. The goal is to predict customer sentiments ('flight ratings') on Twitter towards airlines. For this purpose we provide two datasets. The first one is used for training and testing the sentiment model and the second one is used for predicting the sentiments of new tweets.
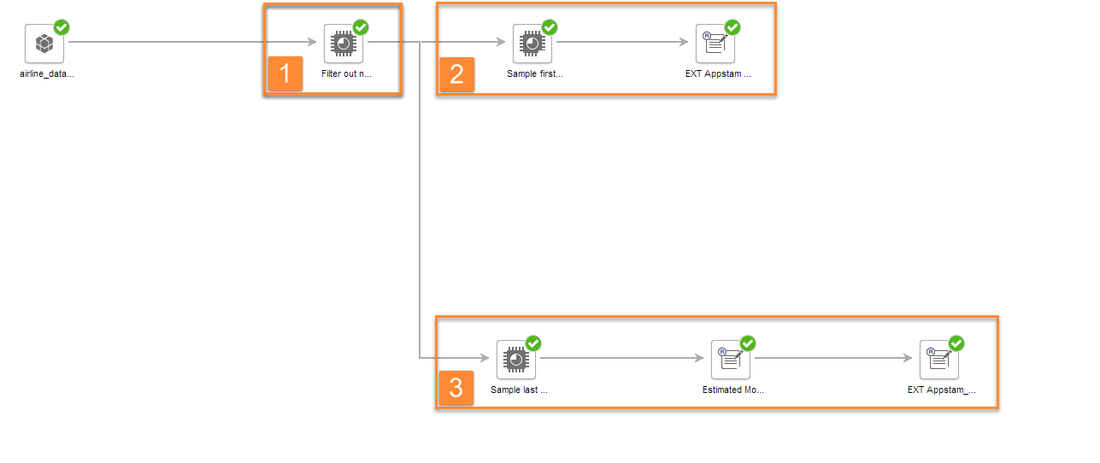
The next figure shows how the model is trained and tested:
The following extended example shows how you could use the extension in a productive scenario. The goal is to predict customer sentiments ('flight ratings') on Twitter towards airlines. For this purpose we provide two datasets. The first one is used for training and testing the sentiment model and the second one is used for predicting the sentiments of new tweets.
The next figure shows how the model is trained and tested:
The original data set contains two columns that we base our analysis on: Customer tweets are collected in the column 'text' and customer sentiments are collectd in the target column 'airline sentiment'. The sentiments expressed by customers were labeled 'positive', negative' and 'neutral'. We load the csv file in SAP Predictive Analytics Expert Mode and follow a three step procedure:
- In the first step we prepare the data set by filtering out the 'neutral' tweets.
- In the next step we sample 3000 tweets, apply our extension to train the model and save the model for later use.
- For testing purposes we sample 1000 tweets and apply the previously saved model. To assess the model we use the extension Appstam Simple Confusion Matrix and compute the ACC.

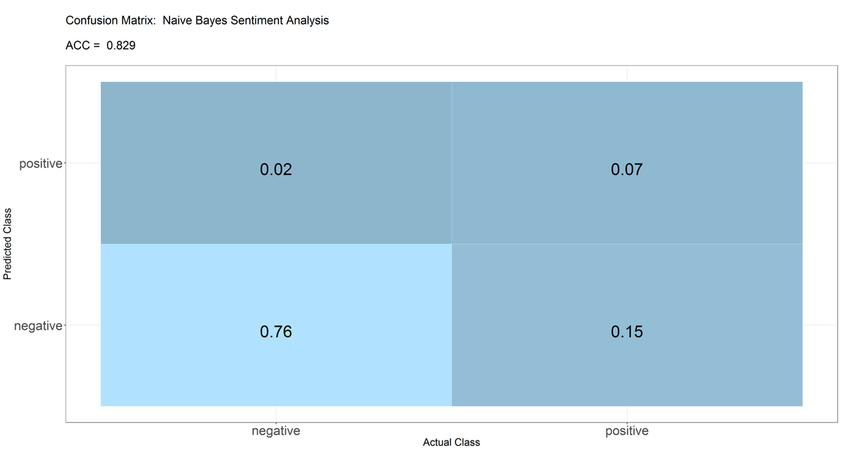
To test the accuracy of our model we apply the extension Appstam Simple Confusion Matrix. The following figure shows the output of the confusion matrix. The model has an accuracy of 83%. In addition, the confusion matrix reveals that most of the misclassified tweets are 'positive' ones we predict to be 'negative'. In a further step we could go back to feature selection and try to increase the discriminatory power for 'positive' tweets.
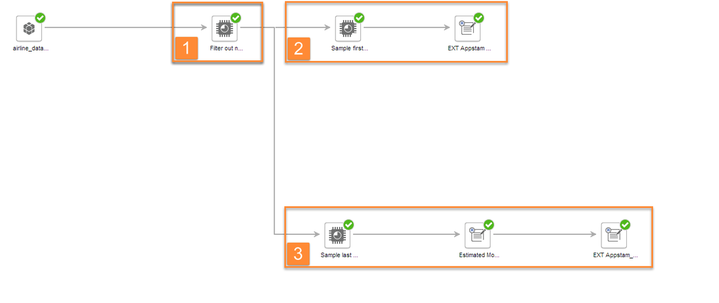
For prediction purposes we load a second data set in a new PA document which contains new unlabeled customer feedback. We save our final model from the previous analysis as a spar file and import it to the new document. The next figure provides an overview of the prediction process:

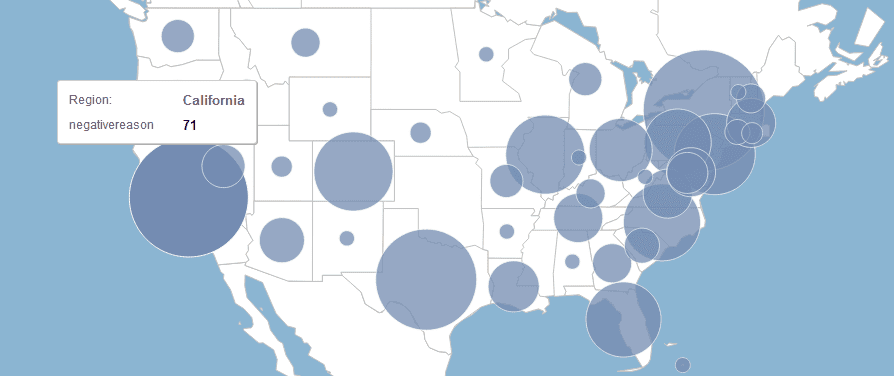
Predictive Analytics provides the possiblity to visually explore data with maps, allowing also to drill down:
Disclaimer
Please note that this component is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes. The extension is in a beta version.
Please note that this component is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes. The extension is in a beta version.
Contact
If you have any suggestions or are interested in a customized version that suits your requirements, feel free to contact us under [email protected]. Thank you for your feedback.
If you have any suggestions or are interested in a customized version that suits your requirements, feel free to contact us under [email protected]. Thank you for your feedback.
