
Custom R Component - Filter Missing Values
Introduction
Exploring and preparing data is a crucial step in every data science project. The handling of missing values influences the accuracy of the subsequent inference. If the relative amount of missing values is negligible it is safe to exclude the affected rows from the analysis. This extension supports the exploration and preparation process by providing summary statistics on missing values and the capability to filter out rows which contain missing entries.
How to upload the component in SAP Predictive Analytics
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Usage
These parameters can be set by the user:
Exploring and preparing data is a crucial step in every data science project. The handling of missing values influences the accuracy of the subsequent inference. If the relative amount of missing values is negligible it is safe to exclude the affected rows from the analysis. This extension supports the exploration and preparation process by providing summary statistics on missing values and the capability to filter out rows which contain missing entries.
How to upload the component in SAP Predictive Analytics
The component can be downloaded as .spar file from GitHub. Then deploy it as described here. You just need to import it through the option "Import/Model Component", which you will find by clicking on the plus-sign at the bottom of the list of the available algorithms.
Usage
These parameters can be set by the user:
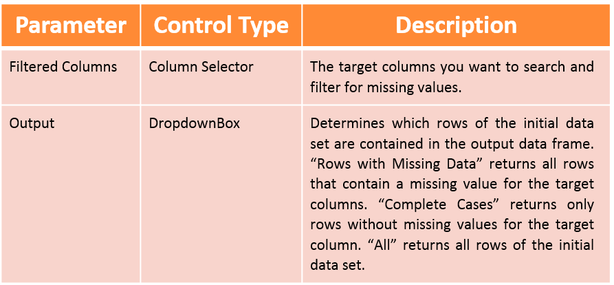
Note: If the entire data set does not contain any missing values the entire data set is returned as an output, irrespective of the specification of the parameter “Output”. The algorithm summary always includes the entire unfiltered data set.
Algorithm Summary
The algorithm summary is case dependent:
Example
For testing purposes, we provide the data set income_data, which contains information on 150 persons: Their names, gender, location and income. In this example we configure the extension to filter for all columns and return the data frame of complete cases. The summary statistic displays an overview of the missing values contained in the data set:
Algorithm Summary
The algorithm summary is case dependent:
- No missing values: If the data set does not contain any missing values we’ll let the end-user know.
- Missing values: If the data does contain missing values two summary statistics are provided:
- Overview missing values: A table to get a better understanding of the pattern of missing data (Please refer to the example for a detailed description of this table).
- Percentage of missing values: A table with the percentage of missing values for every feature.
Example
For testing purposes, we provide the data set income_data, which contains information on 150 persons: Their names, gender, location and income. In this example we configure the extension to filter for all columns and return the data frame of complete cases. The summary statistic displays an overview of the missing values contained in the data set:

The first two rows of the table read as follows: There are 123 cases which do not contain any missing values. There is one case which contains a missing value for the variable name.
The first column shows the number of rows affected. The last column shows how many values are missing for every single case. So for instance, the third row reads: In six cases there is one missing value. This missing value is for the variable gender. The last row sums up the absolute number of missing values per variable. The absolute number of missing value for the entire data set is depicted in the last cell as 39.
The second table displays the percentage of missing values per variable. As a rule of thumb if missing values for a feature exceed 5% one should exclude this feature from the subsequent analysis. This is the case for city and gender with 11.33 and 12 percent.
Disclaimer
Please note that this component is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes. The R code and the GPL3 license can be found in the package appstamDC (Appstam Data Check).
Contact
If you have any suggestions or project inquiries, feel free to contact us under [email protected]. Thank you for your feedback.
The first column shows the number of rows affected. The last column shows how many values are missing for every single case. So for instance, the third row reads: In six cases there is one missing value. This missing value is for the variable gender. The last row sums up the absolute number of missing values per variable. The absolute number of missing value for the entire data set is depicted in the last cell as 39.
The second table displays the percentage of missing values per variable. As a rule of thumb if missing values for a feature exceed 5% one should exclude this feature from the subsequent analysis. This is the case for city and gender with 11.33 and 12 percent.
Disclaimer
Please note that this component is provided as-is without any guarantee or support. Please test the component to ensure it works for your purposes. The R code and the GPL3 license can be found in the package appstamDC (Appstam Data Check).
Contact
If you have any suggestions or project inquiries, feel free to contact us under [email protected]. Thank you for your feedback.
